
相信很多小伙伴都已经知道,在最新一代的英特尔® 酷睿™ Ultra 移动端处理中已经集成了被称为 NPU 的神经网络加速处理器,以提供低功耗的 AI 算力,特别适合于 PC 端需要长时间稳定运行的 AI 辅助功能,例如会议聊天软件中的自动抠像,或是画面超分辨率等应用。而 OpenVINO™ 工具套件也在第一时间对 NPU 进行了适配,接下来就让我们一起看一下如何在英特尔® 酷睿™ Ultra 处理器上搭建基础环境,并调用 NPU 进行模型推理任务。 NPU驱动安装 首先我们需要确保是否安装了最新…

2月22日,Stability AI 发布了 Stable Diffusion 3 early preview,这是一种开放权重的下一代图像合成模型。据报道,它继承了其前身,生成了详细的多主题图像,并提高了文本生成的质量和准确性。这一简短的公告并未附带公开演示,但 Stability今天为那些想尝试的人开放了Waitlist,想等着尝鲜的同学可以注册加入Waitlist。 Waitlist地址:http://stability.ai/stablediffusion3 Stability 表示,其 Stab…
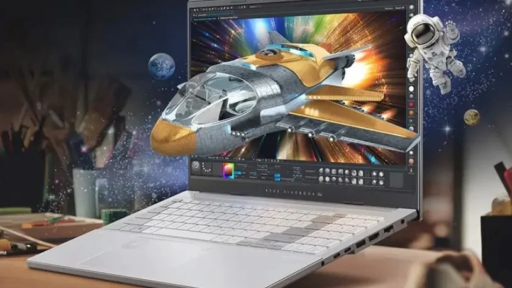
随着移动办公时代的到来,人们对笔记本的要求越来越变得既极致的轻薄,又极致的性能和生产力。华硕2021年推出的Intrepid系列RTX全能AI轻薄本,就是为满足市场这一需求趋势而打造的产品。该系列拥有高品质OLED屏幕,性能优异,具有超高的购买价值。自推出以来,即深受学生和上班族尤其是创意工作者的喜爱。 1月29日20点30分,最新款华硕Fearless Pro15 2024正式发布。这也是首款Core Ultra9+RTX4060全能AI轻薄本。今天我们就通过评测来看看这款将轻薄性能与AI创意生产力融为一体的产品…

NVIDIA在2月13日发布了Chat With RTX,这是一款类似于ChatGPT的免费个性化 AI 聊天机器人,可以在配备 Nvidia RTX 显卡的 PC 上本地运行。它使用Mistral或Llama开放权重LLM,可以搜索本地文件并回答有关它们的问题。本文中我们一起来了解一下Chat with RTX并搭建demo实际体验一下它的能力。 什么是Chat with RTX Chat With RTX 是一款演示应用程序,可让您个性化连接到自己的内容(文档、笔记、视频或其他数据)的 GPT 大语言模型 (L…

在Meteor Lake平台上,英特尔通过神经处理单元 (NPU) 将人工智能直接融入芯片中,实现桌面电脑平台的AI推理功能。神经处理单元 (NPU) 是一种专用人工智能引擎,专为运行持续的人工智能推理工作负载而设计。与即将推出的支持深度人工智能集成的 Windows 版本(预计将于 2024 年夏季推出)搭配,Meteor Lake 可能预示着人工智能 PC 时代的开始,计算机可以利用人工智能来简化我们的计算体验,并使笔记本电脑和台式机的功能呈指数级增长。本文主要介绍在Ubuntu系统上如何启用NPU功能加速AI…

本文介绍Stable Diffusion WebUI在使用上的其它小知识,比如怎样使用额外网络(Extra Network),合并模型,安装扩展功能,安装中文界面,查看提示词参数等。 使用额外网络 除了根据需求切换ckpt模型外,也可以额外叠加几层网路(Extra networks)小模型来改善画风,并改善生成特定物件、角色的准确度。 例如使用Anything模型生图,再搭配”Taiwan-doll-likeness LoRA”就能转成真人风格而不用依赖许多提示词,並且可以一次叠很多个,就像套多层滤镜一般。 跟ck…

本章所討论的训练模型仅为自用用途,若要分享训练的模型也应遵照开源的原则分享。 为什么要训练自己的模型 训练自己的模型可以在现有模型的基础上,让AI懂得如何更景区生成/生成特定的风格、概念、角色、姿势、物件。 举例来说,如果喂给AI十几张我精挑细选的「Hara老师绘制的、不同角度、FGO的斯卡萨哈」做训练,那么就能让AI更懂得如何生成斯卡萨哈的脸部,风格也会比较固定。 以下是一个具体例子,透过使用自行训练的HyperNetwork,便改善单靠Anything模型无法生成出Hara老师画风的缺点。在不使用HyperNe…

内部绘制(inpaint)是用AI填充涂黑(遮罩)区域的技术,例如给图片的角色换衣服。或是反过来:让AI把图片空白的地方绘制完成(outpaint)。可以想像成让AI帮您修图,用于在图中新增或去除物件。此功能位于img2img下的Inpaint页面。 1. 参数解说 Mask blur 图片上的笔刷毛边柔和程度。 Mask mode 选择要让AI填满涂黑区域(Inpaint masked),或是填满未涂黑区域(Inpaint not masked)。 Masked content 要填充的內容。 Inpaint a…

图生图(img2img)是让AI参照现有的图片生图,源自InstructPix2Pix技术。例如:上传一张真人照片,让AI把他改绘成动漫人物;上传画作线稿,让AI自动上色;上传一张黑白照,让AI把它修复成彩色相片。这个功能位于img2img标签页。 1. 实际操作 2. 参数解说 部份参数与文生图的参数重叠,这里不赘述。 Resize mode 裁切模式 决定要对上传的图片做何种操作。 上传的图片最好与生图设定的一致。 Resize to 依照填入的宽高来生图。 Resize by 依照填入的缩放系数来生图,然后缩…

文本到图像生成模型是一种机器学习模型,一般以自然语言描述为输入,输出与该描述相匹配的图像。文生图模型通常结合了一个语言模型,负责将输入的文本转化为机器描述,而图像生成模型则负责生成图像。最有效的模型通常是用从互联网上抓取的大量图像和文本数据训练出来的。 开启Stable Diffusion WebUI网页后,第一个看到的是以下画面,这就是文生图的页面。 生图流程为在左上角填入提示词,勾选左下角的生图参数,再点选右上角生成图片。其余SD WebUI的功能用法大抵都按照此逻辑设计,有些参数是通用的。 需要中文界面的可以…

 今日访客人数 :
今日访客人数 :  本月访客人数 :
本月访客人数 :  今年访客人数 :
今年访客人数 :  总访客人数 : 455644
总访客人数 : 455644 今日浏览量 :
今日浏览量 :  总浏览量 :
总浏览量 :  在线总人数 :
在线总人数 : 您的IP地址 : 216.73.216.87