
人工智能领域的发展永无止境!随着最近发布的 YOLO V10 版本,物体检测领域取得了长足进步。那么它与其他版本有何不同?它在英特尔平台上通过 OpenVINO 框架运行的性能怎样?本文将为大家解答这个问题。
差异与创新
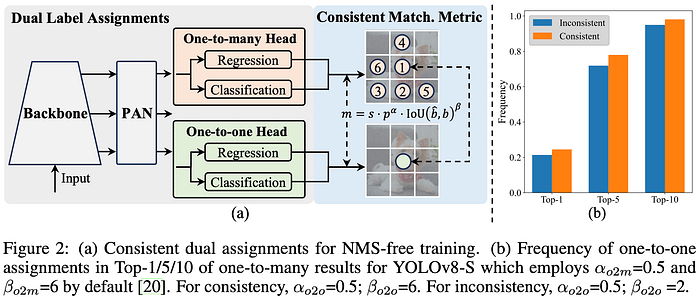
1. 轻量级 Classification Head :
轻量级 classification head 使用深度可分离卷积来减少计算负担。
- 深度可分离卷积:传统卷积过程在每一层同时处理所有通道,计算成本很高。深度可分离卷积将此过程分为两个独立的步骤:深度卷积和点对点卷积。
- 1-深度卷积:每个过滤器仅卷积输入体积的一个通道。
- 2-逐点卷积:使用 1×1 卷积将通道大小的深度卷积的输出结合起来。
- 该方法显著降低了计算成本和参数数量,从而创建更快、更轻的模型。
2. 空间通道解耦下采样:
空间通道分解下采样通过分离空间衰减和通道调制来最大限度地减少信息丢失和计算成本。
- 空间缩减:用于缩减图像或特征图的空间尺寸(宽度和高度)的操作。例如,可以使用池化或步幅卷积来完成。
- 通道调制:用于改变特征图的通道大小(深度)。通常使用 1×1 卷积或其他通道缩减技术。
- 解耦:传统方法中,空间和通道操作是一起进行的,这会导致信息丢失。分解方法通过单独执行这些操作来优化每个步骤,从而减少信息丢失和计算成本。
3. 排序引导块设计:
序列引导块设计根据内在阶段冗余调整块设计,从而确保最佳参数利用率。
- 内在阶段冗余:模型的不同层或块中可能存在冗余或重复信息。这意味着某些层或块携带的信息比其他层或块少。
- Rank-Guided:对每个块或层承载的信息量进行排序评估,承载信息量较少的块在计算和参数方面进行优化。
- 块设计:根据此排名,优化每个块的设计和参数分配。这可以提高模型的整体性能,同时最大限度地减少不必要的计算和参数使用。
这三项效率增强功能可确保对象检测和分类模型运行得更快、更高效。轻量级分类头可减少计算负荷,空间通道解耦下采样可最大限度地减少信息损失,而等级引导块设计可确保最佳参数使用。这些创新可提高模型的准确性和运行速度。
4. 大核卷积:
大核卷积是一种卷积过程,其设计覆盖的区域比典型的卷积层更大。
在传统的卷积层中,过滤器大小(或内核大小)通常较小,例如 3×3 或 5×5。这些过滤器通常用于从给定特征图的一小部分中学习特征。
大核卷积对于识别大面积区域(例如远处的物体)上的特征特别有用。此外,一般来说,它允许更全面的特征提取,同时考虑到更广泛的背景。
5. 部分自我注意力(PSA):
自注意力机制是一种通过考虑特征图中每个像素与其他像素的关系来丰富其表示的机制。经典的自注意力机制考虑所有像素之间的完全连接,这会增加计算成本。部分自注意力仅关注近距离像素之间的关系,而不是这种完全连接。这足以以较小的计算成本捕获特征图中的重要关系。部分自注意力可以帮助模型更好地泛化,同时引入最小的开销来改善全局表示。特别是,它可能更有效地捕捉长距离关系。
这些机制是用于提高卷积网络 (CNN) 和自注意力机制性能的创新技术。大核卷积有助于通过考虑更广泛的背景来提取更全面的特征,而部分自注意力则专注于以最小的额外成本捕捉重要关系,以改善全局表示。
经过这些创新,让我们来看看这些模型的比较情况:
模型比较
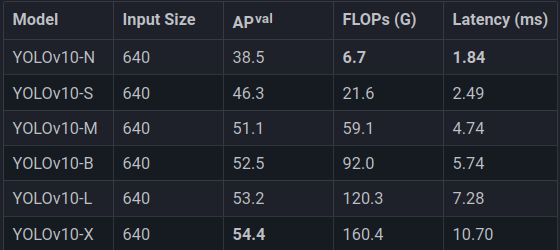
除了传统的 Nano、Small、Medium、Large 和 Extra-Large 型号外,YOLOv10 还推出了一种名为“Balanced” 的新模型。该型号旨在通过增加宽度来提供更高的精度,同时严格解决性能问题。这种方法旨在提供适合用户各种需求的平衡。
“Balanced” 模型的主要目标是在宽度和准确度之间取得平衡。宽度允许模型输入更多数据和更复杂的结构,从而获得更深入的理解和更准确的预测。然而,宽度的增加会对性能产生负面影响。因此,“Balanced” 模型旨在在增加宽度的同时优化性能。这在速度和效率方面改善了用户体验,同时保持了实现更高精度所需的深度和复杂性。
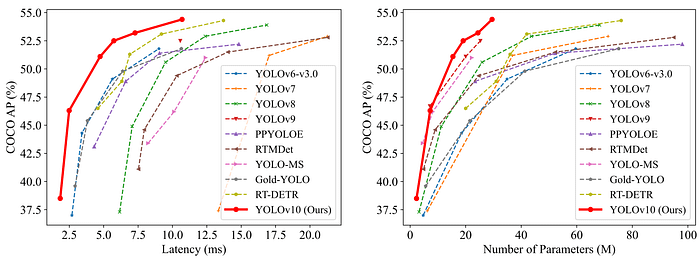
与其他模型相比,尽管参数数量较少,但我们发现准确度和性能更高。
我们如何将 YOLOv10 与 OpenVINO 一起使用,其使用取决于 Ultralytics API?
安装 YOLOv10 和 OpenVINO:
首先我们需要进行必要的安装:
pip install git+https://github.com/THU-MIG/yolov10.git
pip install openvino openvino-dev通过这些命令,必要的库的安装就完成了。
现在我们需要将 PyTorch 格式的 YOLO 模型转换为 OpenVINO IR 格式。但为此,常用的 Ultralytics 导出命令会显示某些错误。这是由于层差异造成的。那么我们如何进行这种转换呢?
如果您尝试使用标准导出命令进行转换,则在 ONNX 后转换为 IR 格式时会出现这样的错误:
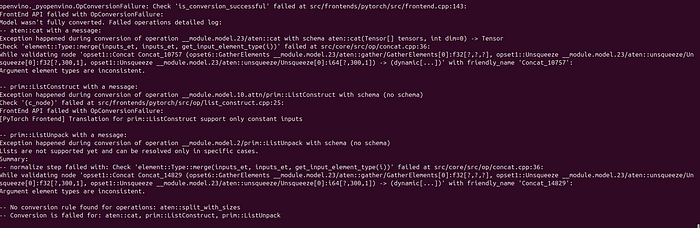
那么我们如何解决这个问题呢?首先,对于 Ubuntu,我们需要在安装上述库后更新 PATH。这完全因计算机而异。因此,如果用户已经添加了此路径 /home/root/.local/bin,不会出现任何问题。但是,如果没有,则会出现以下警告:
WARNING: The scripts ultralytics and yolo are installed in ‘/home/root/.local/bin’ which is not on PATH.这将导致进程失败。为此,必须先调整 PATH 设置,将路径加入环境变量:
export PATH=$PATH:/home/root/.local/bin但如果我们希望它持久化,我们可以使用 .bashrc:
nano ~/.bashrc在文件中添加如下命令行:
export PATH=$PATH:/home/root/.local/bin添加此行后,我们的 PATH 现在将变为永久的。
最后,我们使用 source 命令更新我们的 bash 文件:
source ~/.bashrc现在我们可以进行转换了。
首先你需要从这个地址下载你想要使用的模型:
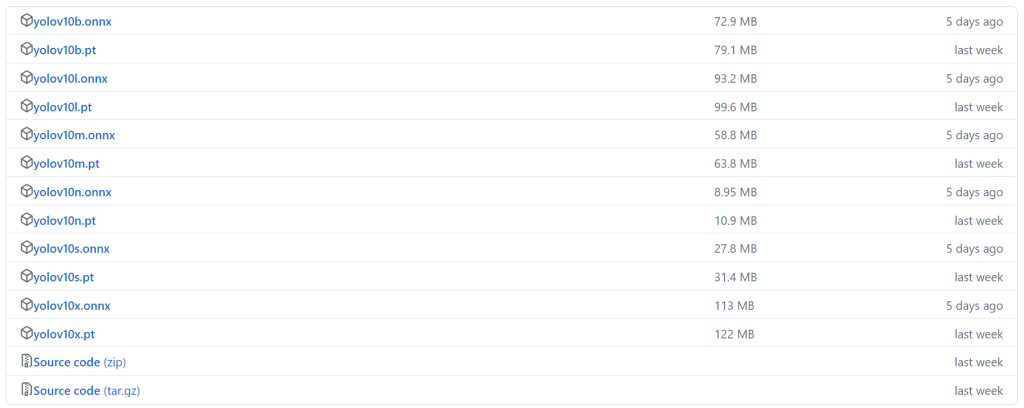
接下来把模型放到 python 代码将要运行的文件夹中。将要运行的 python 代码如下:
import types
from ultralytics.utils import ops
from ultralytics import YOLOv10
import torch
def v10_det_head_forward(self, x):
one2one = self.forward_feat([xi.detach() for xi in x], self.one2one_cv2, self.one2one_cv3)
if not self.export:
one2many = super().forward(x)
if not self.training:
one2one = self.inference(one2one)
if not self.export:
return {"one2many": one2many, "one2one": one2one}
else:
assert self.max_det != -1
boxes, scores, labels = ops.v10postprocess(one2one.permute(0, 2, 1), self.max_det, self.nc)
return torch.cat(
[boxes, scores.unsqueeze(-1), labels.unsqueeze(-1).to(boxes.dtype)],
dim=-1,
)
else:
return {"one2many": one2many, "one2one": one2one}
model = YOLOv10("yolov10n.pt")
model.model.model[-1].forward = types.MethodType(v10_det_head_forward, model.model.model[-1])
model.export(format="openvino", dynamic=True ,half=True)执行此命令后,我们导出的模型将在同一目录中创建,名称为yolov10n_openvino_model。
PyTorch 与 OpenVINO 性能比较
在我的计算机上,配备 Intel(R) Core(TM) i7–7560U CPU @ 2.40GHz,我将首先使用 PyTorch 格式的模型,即 640×640 和 Half,即 fp16:
from ultralytics import YOLOv10
model = YOLOv10("yolov10n.pt")
model.predict(source=0, imgsz=640, show=True)使用此命令,我首先使用 PyTorch 运行模型,结果如下:

延迟范围从 70 到 100。那么使用 OpenVINO 会如何呢?
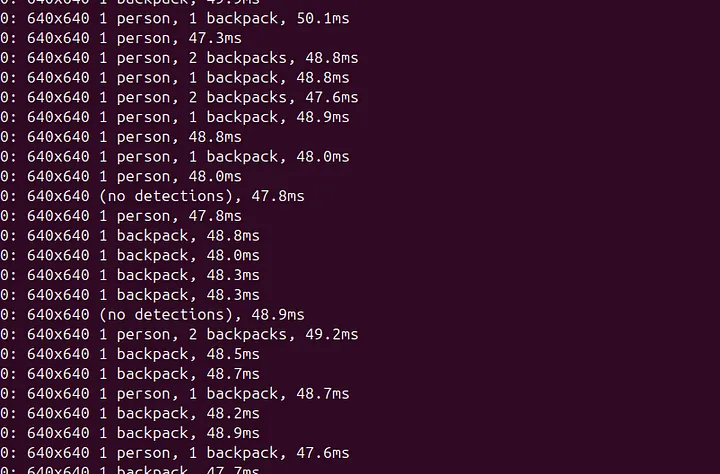
结果在 40 至 50 毫秒之间变化。这个性能非常棒!

 今日访客人数 :
今日访客人数 :  本月访客人数 :
本月访客人数 :  今年访客人数 :
今年访客人数 :  总访客人数 : 448569
总访客人数 : 448569 今日浏览量 :
今日浏览量 :  总浏览量 :
总浏览量 :  在线总人数 :
在线总人数 :
文章评论