
YOLOv10由清华大学研究人员使用Ultralytics Python 软件包开发,通过改进模型架构和消除非最大抑制 (NMS),为实时物体检测提供了一种新方法。这些优化可以以较低的计算需求实现最先进的性能。大量实验表明,YOLOv10 在各种模型规模上都提供了出色的准确率-延迟权衡。
我以前也在各种项目中使用过 YOLO 模型,因为在预训练模型中,YOLO 模型在性能和效率方面比其他模型更突出。然而,由于依赖非最大抑制 (NMS) 和架构效率低下,实时对象检测面临挑战。YOLOv10 通过消除 NMS 并采用注重效率和准确性的设计策略来解决这些问题。
软件架构
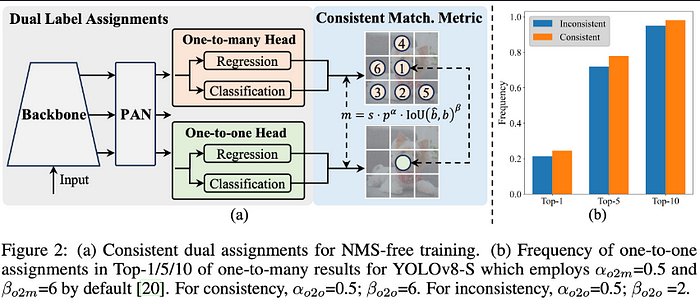
- Backbone:负责特征提取,YOLOv10 中的 Backbone 采用了增强版 CSPNet(Cross Stage Partial Network),以改善梯度流,减少计算冗余。
- PAN:PAN用于聚合不同尺度的特征并将其传递到头部。它包括 PAN(路径聚合网络)层,用于有效的多尺度特征融合。
- One-to-many Head:在训练期间为每个对象生成多个预测,以提供丰富的监督信号并提高学习准确性。
- One-to-one head:在推理过程中为每个对象生成单个最佳预测,以消除对 NMS 的需要,从而减少延迟并提高效率。
模型变体和性能
YOLOv10有六种模型:
- YOLOv10-N:适用于资源极其受限的环境的纳米版本。
- YOLOv10-S:平衡速度和准确性的小版本。
- YOLOv10-M:通用的中等版本。
- YOLOv10-B:平衡版本,增加了宽度以获得更高的准确性。
- YOLOv10-L:大型版本,可实现更高的准确度,但会增加计算资源。
- YOLOv10-X:超大版本,可实现最大准确率和性能
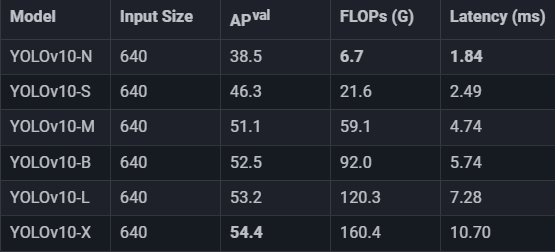
性能比较
让我们看看在 COCO 等标准基准上测试的不同模型在延迟和准确性方面的比较。
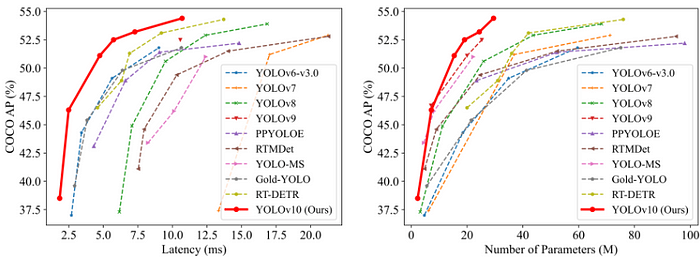
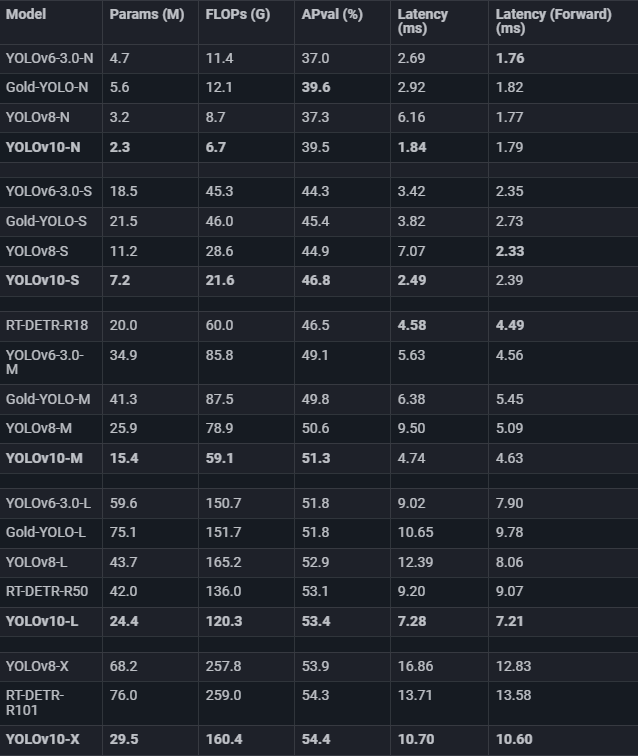
显然,YOLOv10 是实时物体检测应用的尖端技术,它以更少的参数提供更高的准确性和速度性能。
训练 YOLOv10 进行自定义对象检测
首先,克隆官方YOLOv10 GitHub存储库以下载必要的yolov10n 模型。
!pip install -q git+https://github.com/THU-MIG/yolov10.git
!wget -P -q https://github.com/jameslahm/yolov10/releases/download/v1.0/yolov10n.pt您可以在Roboflow Universe上试验任何自定义项目,创建自己的数据集,甚至可以使用英特尔赞助的RF100数据集。在本文中,我将使用预先准备的数据集,该数据集旨在检测 X 射线图像中的危险物品。
使用 Roboflow API 以 YOLOv8 格式下载您的模型。
!pip install -q roboflow
from roboflow import Roboflow
rf = Roboflow(api_key="your-api-key")
project = rf.workspace("vladutc").project("x-ray-baggage")
version = project.version(3)
dataset = version.download("yolov8")指定参数和文件路径,然后开始模型训练。
!yolo task=detect mode=train epochs=25 batch=32 plots=True \
model='/content/-q/yolov10n.pt' \
data='/content/X-Ray-Baggage-3/data.yaml'示例 data.yaml 文件如下:
names:
- Gun
- Knife
- Pliers
- Scissors
- Wrench
nc: 5
roboflow:
license: CC BY 4.0
project: x-ray-baggage
url: https://universe.roboflow.com/vladutc/x-ray-baggage/dataset/3
version: 3
workspace: vladutc
test: /content/X-Ray-Baggage-3/test/images
train: /content/X-Ray-Baggage-3/train/images
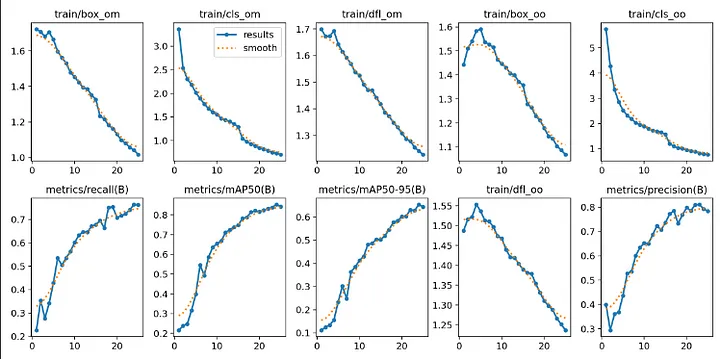
val: /content/X-Ray-Baggage-3/valid/images我们来看看结果。
Image(filename='/content/runs/detect/train/results.png', width=1000)
让我们预测测试数据并在 5×2 的网格中显示结果。
from ultralytics import YOLOv10
model_path = '/content/runs/detect/train/weights/best.pt'
model = YOLOv10(model_path)
results = model(source='/content/X-Ray-Baggage-3/test/images', conf=0.25,save=True)import glob
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
images = glob.glob('/content/runs/detect/predict/*.jpg')
images_to_display = images[:10]
fig, axes = plt.subplots(2, 5, figsize=(20, 10))
for i, ax in enumerate(axes.flat):
if i < len(images_to_display):
img = mpimg.imread(images_to_display[i])
ax.imshow(img)
ax.axis('off')
else:
ax.axis('off')
plt.tight_layout()
plt.show()
结论和建议
- 在撰写本文时,我在多个数据集上训练了 YOLOv10n 模型,这耗尽了我在 Colab 上的免费 T4 GPU 限制。当您在 Colab 环境中训练模型时超出限制时,T4 GPU 会受到限制。您可以通过使用不同的 Google 帐户登录来解决此问题。
- 由于技术发展迅速,我认为学习计算机视觉和大型语言模型中的主要概念而不局限于单一技术是有益的。为了适应这一点,向这些技术的开发人员学习是有帮助的。

 今日访客人数 :
今日访客人数 :  本月访客人数 :
本月访客人数 :  今年访客人数 :
今年访客人数 :  总访客人数 : 451339
总访客人数 : 451339 今日浏览量 :
今日浏览量 :  总浏览量 :
总浏览量 :  在线总人数 :
在线总人数 :
文章评论