
本文介绍Stable Diffusion WebUI在使用上的其它小知识,比如怎样使用额外网络(Extra Network),合并模型,安装扩展功能,安装中文界面,查看提示词参数等。
使用额外网络
除了根据需求切换ckpt模型外,也可以额外叠加几层网路(Extra networks)小模型来改善画风,并改善生成特定物件、角色的准确度。
例如使用Anything模型生图,再搭配”Taiwan-doll-likeness LoRA”就能转成真人风格而不用依赖许多提示词,並且可以一次叠很多个,就像套多层滤镜一般。

跟ckpt大模型比起来,这类模型档案都很小,主要用来微调现有的模型。小模型有嵌入(Embedding)、超网路(HyperNetwork)、LoRA三种,文件名以.pt或.safetensors结尾,目前最热门的为”LoRA”。更方便的是因为档案小,自行训练喜欢的人物模型成本並不高。
1. 安装小模型
Civitai有很多小模型可以下载。下载时需注意模型是哪一种。
Embedding请放stable-diffusion-webui资料夹下的embeddings
HyperNetwork放到stable-diffusion-webui/models/hypernetworks。
LoRA放到stable-diffusion-webui/models/Lora。
如果要显示小模型缩图,将图片取跟该模型一样的档名,并放到该模型的资料夹。例如在Taiwan-doll-likeness.safetensors所在的资料夹放一张Taiwan-doll-likeness.png。
2. 小模型使用方法
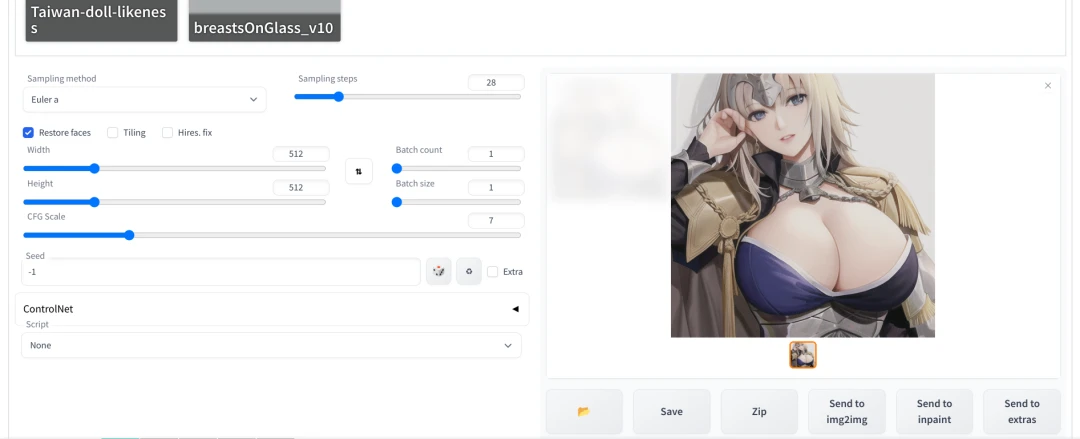
- 进入WebUI,点选右上角Show extra networks

- 这样就会出现额外模型列表。以LoRA为例,点选小模型的卡片便会将其加到提示词栏位,提示词栏位会出现
< >,表示要在绘图时使用LoRA。
- 接着再加上其他提示词,生图即会有使用LoRA的风格。

- 如果生出来的图片太诡异,调整提示词栏位每个LoRA后面的数字,控制权重。

- 这样看起来是不是不一样了?
3. 安装与使用VAE
VAE (variational autoencoder)可以让算出来的图片色彩更漂亮,改善图片顏色灰灰暗暗的问题。
Hentai Diffusion这类模型內建VAE,SD WebUI在生图时会自动侦测并套用;Anything这类的模型要另外下载VAE;VAE的下载点通常跟模型下载页面放在一起。
如果要使用VAE,下载VAE模型后,將其放到stable-diffusion-webui/models/VAE资料夹。
接著点选Settings → Stable Diffusion → SD VAE,选取要使用的VAE,再点选Apply Settings,此后生图就会一律使用指定的VAE。
合并模型
此页面可以将最多三个的存档点模型合并,以融合出更好的效果。

合并模型会占用大量硬盘空间,看用途决定。有时想要生成某个人物,用基础模型搭配LoRA会是比较经济实惠的方法,不必频繁合并模型。
安装扩展功能
注意:安装扩充功能可能会导致Stable Diffusion WebUI无法启动,或是启动变慢。如果遇到bug,您应当优先到扩充功能开发者的Github储存库回报,而非直接到AUTOMATIC1111的储存库询问。
1. 用图形界面安装
- 在 命令行参数加入
--enable-insecure-extension-access才能从图形界面装扩充功能。 - 最简单的方法就是点选Extensions → Available的
Load from:,就会列出可下载安装的扩充功能,点选安装。
- 有些比较新的扩充功能则是要您复制Github储存库网址,並点选选Extensions →
Install from URL,贴上网址再按Install,它会自动完成git clone的操作。
- 在安装扩充功能后,都要点选Installed → Apply and restart WebU,重新载入网页界面。有些则是得关掉终端机,重新启动WebUI。

- 如果未来要更新扩充功能,点选Installed → Check for updates,等待下载完成,然后重启WebUI。您可以在这个界面按取消打勾来停用特定的扩充功能。

2. 用指令安装
Stable Diffusion WebUI的扩充功能目录一律放在extensions文件夹。
- 用指令安装扩充功能前先关闭主程序。
- 接着在
stable-diffusion-webui/extensions资料夹开启terminal,执行git clone指令,安装扩充功能。例如要安装繁体中文翻译的话就是把该储存库复制下来:
git clone https://github.com/benlisquare/stable-diffusion-webui-localization-zh_TW.git- 重新启动SD WebUI,即会看到新安装的扩展功能。
- 未来要一次更新全部扩充功能的话,在 命令行参数加入以下选项,让Stable Diffusion WebUI启动后自动更新所有扩展功能:
--update-all-extension3. 如何移除扩展功能
- 关闭Stable Diffusion WebUI。
- 到
stable-diffusion-webui下的extension文件夹,将要移除的扩充功能文件夹刪除。 - 如果要完全移除扩充功能,將
stable-diffusion-webui下的venv文件夹也刪除,迫使主程序下次启动重新安装pip依赖套件。
安装中文界面
- 繁体中文扩充功能来源: benlisquare/stable-diffusion-webui-localization-zh_TW
- 简体中文扩充功能来源: dtlnor/stable-diffusion-webui-localization-zh_CN
Stable Diffusion WebUI可以透过扩展功能將界面变成中文。
- 进入Extensions页面,取消勾选
localization,再点选Load from:,找到zh_TW Localization或zh_CN Localization,点选Install。
- 到Settings页面,找到左边的Localization,点选
zh-tw或zh-cn,再点选Apply Settings。
- 之后重启WebUI,界面就会变成中文了。
由于SD WebUI的扩充功能发展太快,翻译可能跟不上,建议另外安装双语对照 sd-webui-bilingual-localization,同时显示中文和英文的文字,这样看教学时就不会不到按钮了。
双语扩充功能安装方法:在Extensions页面按Install from URL,填入https://github.com/journey-ad/sd-webui-bilingual-localization,再按Install。
在启用双语扩充功能前,要到Settings → User interface → Localization设为None再重启WebUI才会生效。

查看提示词参数
SD WebUI生成的图片都是PNG档,並会记载生成图片所使用的模型、提示词等资讯。
如果有人分享未修改过的SD WebUI图片,那么你只要把它下载下来,于此界面上传图片,即会显示该图片背后使用的提示词。

不过有些模型会使用 LoRA和其他的小模型,这点可从提示词有无< >来判断。因此有时候完全照抄提示词是不够的,缺少的东西要手动下载。
放大图片分辨率
Stable Difussion WebUI內建AI放大技术,像是ESRGAN,比Waifu2x更强。如果用预设的512×512分辨率就生出不错的图,可以将图片直接通过Extras放大。
1. 实际操作
切换至Extras页面,上传图片,选取放大2倍,点选下面的Upscaler 1中挑一个看起来顺眼的,其余维持预设,按Generate即会得到放大过的图片。

旁边的Batch Process可以一次处理大量图片;Batch from Directory则是从特定文件夹输入放大图片。
2. 参数解说
Scale by
按照此数字的倍数放大
Scale to
放大至指定宽高
Upscaler 1 & Upscaler 2
放大图片的时候可以只用一种放大器,也可以混合使用二种放大器。
Upscaler 2 visibility
第二个放大器的权重。
GFPGAN visibility
GFPGAN脸部修復模型的权重
CodeFormer visibility
CodeFormer脸部修復模型的权重
3. Upscaler效果比较
目前Stable Diffusion WebUI的放大器包含LDSR、BSRGAN、ESRGAN_4x、R-ESRGAN-General-4xV3、R-ESRGAN-General-WDN-4xV3、R-ESRGAN-AnimeVideo、R-ESRGAN-4x+、R-ESRGAN-4x+-Anime6B、ScuNET-GAN、ScuNET-PSNR、SwinIR_4x…
根据Reddit网友在 The DEFINITIVE Comparison to Upscalers一文的比较,总结如下:
- ESRGAN_4x适合用于处理真人照片
- ESRGAN_4x适合用于绘画
- Anime6B适合用于动漫图片,它也可以用来将真人图片转动漫风格

 今日访客人数 :
今日访客人数 :  本月访客人数 :
本月访客人数 :  今年访客人数 :
今年访客人数 :  总访客人数 : 450631
总访客人数 : 450631 今日浏览量 :
今日浏览量 :  总浏览量 :
总浏览量 :  在线总人数 :
在线总人数 :
文章评论