
寻找股票进行投资可能是一个漫长而乏味的过程。如果我们同时使用 AI 和 Python 来创建一个可以加快这一过程的程序会怎么样?在这篇博文中,我将探讨如何使用finvizfinance Python 库来查找“被低估”的股票。然后,我将介绍一种使用 FinBERT(一种预先训练的 NLP 模型)进行情绪分析的方法——可以对这些“被低估”的股票进行分析。
准备工作
首先,我们需要安装所需的库并导入它们。finviz.com是一个提供各种股票分析工具的网站,例如免费的股票筛选器 – 在这里,导入 finvizfinance 的筛选器对象,该对象返回筛选器结果“概述”部分的 Pandas 数据框。
from finvizfinance.screener.overview import Overview然后,导入pandas、csv和os库。这些主要用于操作 csv 文件。
import pandas as pd
import csv
import os筛选潜在股票
现在,按照价值投资方法,目标是整理一份可能被低估的股票清单以供研究。为此,创建一个使用 finvizfinance 库向在线股票筛选器发出请求的函数。以下函数将执行此操作:
def get_undervalued_stocks():
"""
Returns a list of tickers with:
- Positive Operating Margin
- Debt-to-Equity ratio under 1
- Low P/B (under 1)
- Low P/E ratio (under 15)
- Low PEG ratio (under 1)
- Positive Insider Transactions
"""
foverview = Overview()作为价值投资者,我们一般寻找市净率 (P/B) 较低的股票。这表明股价低于公司资产的价值,意味着股票被低估——假设公司没有陷入财务困境。我们还可以查询营业利润率,这是一个很好的指标,可以表明一家公司的管理有多好,以及它从销售中赚取利润的效率有多高。此外,我们希望债务权益比低于 1,这意味着公司的风险较低。
另一个好的指标是最近的市盈率 (P/E) 低于平均水平。因此,我们需要低市盈率和低市盈率增长率 (PEG)。市盈率将公司的股价与其每股收益联系起来。因此,高市盈率可能意味着公司“估值过高”。
最后,我们还好寻找积极的内幕交易。积极的内幕交易是指内部人员购买自己公司的股票。经理和董事对他们经营的公司有独特的了解,因此,如果他们购买此类股票,那么可以合理地假设该公司的前景看好。
filters_dict = {'Debt/Equity':'Under 1',
'PEG':'Low (<1)',
'Operating Margin':'Positive (>0%)',
'P/B':'Low (<1)',
'P/E':'Low (<15)',
'InsiderTransactions':'Positive (>0%)'}这些参数并不完全全面;它们可能针对特定行业,也可能过于严格,甚至在某些情况下过于宽泛。了解您想要投资的业务对于价值投资者来说也很重要,因此您可能需要定义自己的选股策略并研究更个性化的参数。以下是 FINVIZ.com 免费在线股票筛选器的所有可能参数列表:
parameters = ['Exchange', 'Index', 'Sector', 'Industry', 'Country', 'Market Cap.',
'P/E', 'Forward P/E', 'PEG', 'P/S', 'P/B', 'Price/Cash', 'Price/Free Cash Flow',
'EPS growththis year', 'EPS growthnext year', 'EPS growthpast 5 years', 'EPS growthnext 5 years',
'Sales growthpast 5 years', 'EPS growthqtr over qtr', 'Sales growthqtr over qtr',
'Dividend Yield', 'Return on Assets', 'Return on Equity', 'Return on Investment',
'Current Ratio', 'Quick Ratio', 'LT Debt/Equity', 'Debt/Equity', 'Gross Margin',
'Operating Margin', 'Net Profit Margin', 'Payout Ratio', 'InsiderOwnership', 'InsiderTransactions',
'InstitutionalOwnership', 'InstitutionalTransactions', 'Float Short', 'Analyst Recom.',
'Option/Short', 'Earnings Date', 'Performance', 'Performance 2', 'Volatility', 'RSI (14)',
'Gap', '20-Day Simple Moving Average', '50-Day Simple Moving Average',
'200-Day Simple Moving Average', 'Change', 'Change from Open', '20-Day High/Low',
'50-Day High/Low', '52-Week High/Low', 'Pattern', 'Candlestick', 'Beta',
'Average True Range', 'Average Volume', 'Relative Volume', 'Current Volume',
'Price', 'Target Price', 'IPO Date', 'Shares Outstanding', 'Float']现在已经设置了筛选器的过滤器,可以连接到 finviz 筛选器 API 并收集所需的数据。
foverview.set_filter(filters_dict=filters_dict)
df_overview = foverview.screener_view()
if not os.path.exists('out'): #ensures you have an 'out' folder ready
os.makedirs('out')
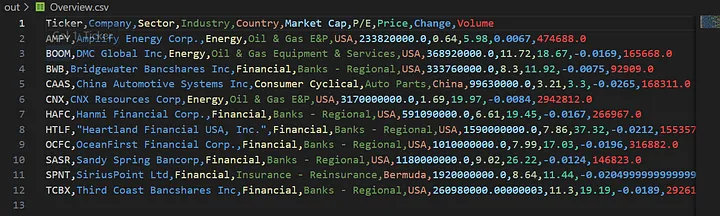
df_overview.to_csv('out/Overview.csv', index=False)
tickers = df_overview['Ticker'].to_list()
return tickers
#print(get_undervalued_stocks())运行上述程序(如果取消注释最后一行)会输出一个股票代码列表,如果进行进一步分析,该列表可以帮助您形成关注列表。建议在匆忙得出结论之前,您可能希望花一些时间手动查看这些公司 – 例如,重点关注损益表或资产负债表。
['AMPY', 'BOOM', 'BWB', 'CAAS', 'CNX', 'HAFC', 'HTLF', 'SASR', 'SPNT', 'TCBX']另外还会在“out”文件夹中找到一个 csv 文件,其中包含这些股票的概览。
使用金融 BERT 进行情绪分析(Sentiment Analysis)
现在,我们有了一份“被低估”的股票清单,可以投资。但是,了解媒体对公司的看法也很重要,最重要的是,了解其股票本身。虽然优秀的价值投资者不应该随波逐流,但了解股票的观点是明智的——因为这有助于评估其价值的根本原因,无论是高估还是低估。
因此,我们需要编写一个程序,以便获取股票筛选器提供的与每只股票相关的最新新闻文章列表。该程序将输出文章的标题、发布日期以及文章中传达的总体情绪——让您可以轻松概览对股票的总体情绪。
准备工作
首先,需要安装并导入所需的依赖项。
Transformers库提供了数千个预先训练的模型,用于对文本、视觉和音频等不同模态执行任务。为了对金融新闻文章进行情感分析,我们将使用ProsusAI预训练模型FinBERT。该模型是通过在金融领域进一步训练 Google 的语言模型 BERT 而建立的。
from transformers import pipeline要从 Yahoo! 下载市场数据新闻,财经API 我们将使用yfinance Python 库。
import yfinance as yf接下来,我们导入Goose(一个 Html 内容/文章提取器,适用于 Python3 的网页抓取工具),以及 requests 库的 get 方法来发送 HTTP 请求并获取财经新闻文章数据。
from goose3 import Goose
from requests import get获取财经新闻文章数据
我们定义一个函数,以股票行情机作为输入,并返回一个包含 3 列的 Pandas 数据框:发布日期、文章标题、文章情感。
Ticker模块将允许您 获取给定股票的最新财经新闻列表。接下来,实例化 Goose 文章提取器和预训练 NLP 模型的管道。
def get_ticker_news_sentiment(ticker):
"""
Returns a Pandas dataframe of the given ticker's most recent news article headlines,
with the overal sentiment of each article.
Args:
ticker (string)
Returns:
pd.DataFrame: {'Date', 'Article title', Article sentiment'}
"""
ticker_news = yf.Ticker(ticker)
news_list = ticker_news.get_news()
extractor = Goose()
pipe = pipeline("text-classification", model="ProsusAI/finbert")调用 get_news() 方法会返回一个字典列表。每个字典都包含有关新闻文章的信息,例如文章的链接和标题。对于列表中的每个字典(文章),在使用 Goose 提取器提取其文本和日期之前,先向文章的链接发送请求。
如果文章的文本超过 512 个单词,则标记索引序列长度将长于FinBERT模型指定的最大序列长度。通过模型运行这样的序列将导致索引错误。虽然有一种方法可以对超过 512 个标记的长文本进行情感分析,但由于本文的重点,这种方法将不作详细说明。
通过将文本传递到管道,模型将为三个标签提供 softmax 输出:正面、负面或中性。概率最大的“标签”将被返回。这将描述给定文本的整体主导情绪。
最后,此函数将“数据”列表转换为 Pandas 数据框并返回它:
data = []
for dic in news_list:
title = dic['title']
response = get(dic['link'])
article = extractor.extract(raw_html=response.content)
text = article.cleaned_text
date = article.publish_date
if len(text) > 512:
data.append({'Date':f'{date}',
'Article title':f'{title}',
'Article sentiment':'NaN too long'})
else:
results = pipe(text)
#print(results)
data.append({'Date':f'{date}',
'Article title':f'{title}',
'Article sentiment':results[0]['label']})
df = pd.DataFrame(data)
return df现在,让我们将这个新函数用于之前获得的股票行情。首先,您需要一个小的辅助函数,它将股票行情的新闻情绪 Pandas DataFrame转换为存储在 out 目录中的 csv 文件。
def generate_csv(ticker):
get_ticker_news_sentiment(ticker).to_csv(f'out/{ticker}.csv', index=False)最后,我们对之前获得的每个股票代码调用此函数:
undervalued = get_undervalued_stocks()
for ticker in undervalued:
generate_csv(ticker)这将创建或更新您的输出目录,其中包含一个概览文件,其中包含所有“被低估”股票的一般数据,以及一个 csv 文件,其中包含对股票的近期情绪的简单概览。
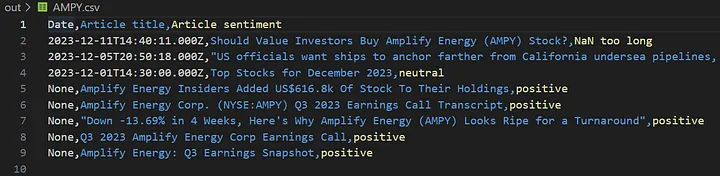
例如,仅通过查看Amplify Energy Insiders (AMPY)上的最新金融文章标题,似乎其他人也同意该股票“被低估了”。
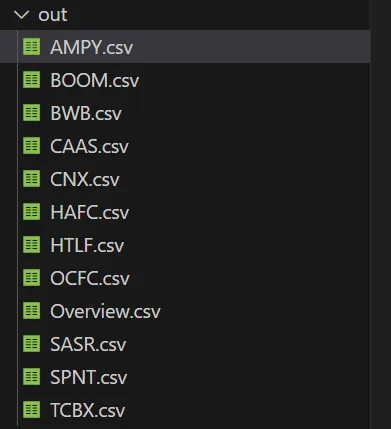
这样,我们的目标就完成了。通过运行这个程序,我们获得了“被低估”股票的列表、这些股票的概述以及最近的财经新闻文章列表——以及它们的整体情绪。通过这些信息,我们可以评估某支股票是否值得买入。

 今日访客人数 :
今日访客人数 :  本月访客人数 :
本月访客人数 :  今年访客人数 :
今年访客人数 :  总访客人数 : 451380
总访客人数 : 451380 今日浏览量 :
今日浏览量 :  总浏览量 :
总浏览量 :  在线总人数 :
在线总人数 :
文章评论